
Authors: Fatih E. NAR, Ben Cushing, Ranny Haiby
Over the years, the Network (aka The Fabric, The Grid) has evolved into the platform itself for applications and services. This shift stems from the nature of distributed systems and the expansion of infrastructure across datacenters, edge locations, and hybrid environments, as well as the growing organizations that touch, use, and depend on it. In that sense, the modern enterprise is a “Living Network” of systems and people, distributed across locations and business units to achieve a common goal; remaining relevant in the market and delivering forecasted returns.
A Cautionary Tale: The Ghost of CoEs Past
In recent years, it has become common practice for organizations to build Centers of Excellence (CoE) to “standardize best practices” and “organize people and teams in a hierarchy.” Unfortunately, many burned millions producing slide decks nobody read, while the actual engineering work happened in Slack channels they weren’t invited to. The race to embrace AI for Networks carries the same risk, only this time it might cost 10x more and fail twice as fast.
Traditional CoEs failed by applying deterministic processes to inherently probabilistic business landscapes. Rigid frameworks and static governance cannot accommodate evolving market behavior or the rapid obsolescence of yesterday’s trends. Consequently, many CoEs prioritized compliance over delivery, leading to eventual dissolution or endless reorganization as they ceased to drive tangible value.
The Illusion of the AI Center of Excellence
As AI/ML adoption accelerates, many organizations are inadvertently replicating the siloed anti-patterns, non-functional practices of the past. A common failure mode involves establishing centralized ‘AI/Data Science’ teams that are structurally isolated from the actual business problems & goals.
By separating data scientists from business domain experts (i.e. subject matter experts -SME-) and core platform teams, companies create a disconnect between AI development and business value reality. This structure leads to a portfolio of theoretical solutions that lack a path to deployment or true business impact. Ultimately, this approach fails because it decouples the AI capability from the operational context (the domain) required to drive value.
The Data Archaeology Problem
Handing years of accumulated legacy data to a segregated AI team is a recipe for failure. Without active participation from domain experts, network engineers, architects, and analysts, data scientists struggle to decipher the context behind undocumented schemas. The result; models built on misinterpreted data that fail to address actual business needs or survive in production.
Business-Driven Architecture: The Antidote
The viable alternative to centralized CoEs is embedding AI capability directly into existing value-generating systems and the people who operate them. The formula for success is specific:
Domain Expertise + AI Capability + DevSecOps → Value Generation
The logical evolution of this architecture is a Community of Practice (CoP); a federated network of domain experts with AI skills, empowered to experiment, iterate, and operationalize AI/ML where the business needs it.
The AI CoP equips teams with operational AI knowledge, shared tooling, and common deployment patterns. This requires upskilling domain experts who already understand the data, integrating them into existing DevSecOps pipelines, and measuring success through business metrics, {MTTD/R for business continuity, Time to Market for new services}, rather than model accuracy alone. The breakthrough; coupling domain context with operational execution.
The Value of Open Source Software
Open-source software provides an excellent starting point for putting this theory into practice.
Telco-AIX is an community driven open-source repository combining open-weight models (Qwen, DeepSeek, Llama, and others) with practical tooling for problems like churn prediction, revenue assurance, fraud management, and predictive maintenance. The architecture leverages RAG for in-house data, vLLM for cost-effective inference, and model chaining to combine ML and GenAI approaches all designed to lower the barrier to entry.
Essedum and Salus, Linux Foundation projects, address fragmentation in network fabric data planes by providing a unified, open-source solution for the full AI lifecycle. Instead of disjointed tools for data ingestion, training, and deployment, Essedum offers a cohesive architecture connecting domain-specific data with AI models. Salus adds responsible AI guardrails, enabling network operators to move from experimental pilots to scalable, autonomous network management without proprietary lock-in.
The Platform Evolution: From Kubernetes Clusters to AI-Native Platforms
With open models now achieving performance parity at one-tenth the cost of closed AIaaS APIs, the “buy vs. build” calculus has shifted. The solution is architectural; run open models (DeepSeek, Qwen, Llama, and others) on your existing Kubernetes clusters using vLLM and KServe.
This approach solves three critical problems. First, it dramatically lowers costs. Second, data never leaves your infrastructure. Third, it enables a true hybrid strategy where inference runs exactly where needed from far edge to data center core.
AI inference is not a replacement for what you have; it is an enrichment of the distributed systems you already operate. Your existing Kubernetes expertise translates directly:
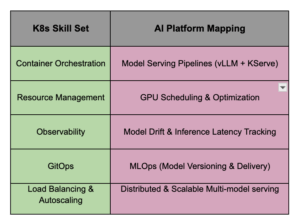
You don’t need a PhD in AI/ML to benefit from it. By focusing on operationalization, you can embed intelligence into application stacks, optimize platform utilization, and manage AI-augmented deployments. You bring the production experience that isolated data science teams often lack.
Start with Experimentation: The Low-Risk Path to AI-Native Infrastructure
Here’s the reality; you don’t need a massive transformation initiative to begin. You need permission to experiment and a willingness to measure outcomes honestly.
The old CoE model failed because it demanded perfection upfront architecture reviews, governance frameworks, network-wide rollout plans before a single line of code shipped. That deterministic mindset killed innovation.
AI systems are probabilistic by nature. They improve through iteration, not proclamation. Your DevSecOps teams already know this; they’ve been doing continuous delivery, A/B testing, and incremental rollouts for years. Apply that same discipline to AI workloads.
The Experimentation Playbook
- Step 1: Pick a low-hanging fruit. Form a small tiger team around a well-understood problem with clear solution paths; anomaly detection in revenue assurance, support ticket classification, or predictive maintenance etc.
- Step 2: Experiment on existing infrastructure. Use your current Kubernetes clusters with a Data Feature Store, Jupyter Notebooks, and vLLM serving a small open-weight model (Qwen3-4B, Llama3.1-8B, or similar).
- Step 3: Augment, don’t rebuild. Integrate the inference endpoint into existing workflows (ticketing systems, monitoring dashboards) and instrument with your standard observability stack (OpenTelemetry, Prometheus, Loki, Grafana).
- Step 4: Iterate on business metrics. Focus on outcomes; reduced triage time, SLA compliance rather than raw model accuracy. Tune prompts and leverages RAG for better context using real-world feedback.
- Step 5: Grow the CoP. Your tiger team becomes a community. Encourage further experimentation, capture lessons learned across teams, and evolve standards based on operational reality.
Why Does This Work?
Unlike the heavy lift of a CoE, this approach leverages existing infrastructure and domain experts to ship production-ready capabilities faster and more reliably. It eliminates the “translation layer” between requirements and implementation, creating an environment where experiments are low-cost, feedback is rapid, and sunk costs are minimal.
This is how DevSecOps culture works; start small, automate relentlessly, measure religiously, scale incrementally.
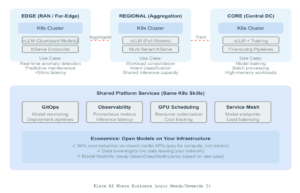
This is how AI should work for networks; not as a separate initiative, but as a capability embedded in the teams that already ship production systems.The result is AI that delivers business value in weeks, not quarters.
The Bottom Line
The Community of Practice model matches AI’s nature. Effective intelligence depends on tight problem-data-model coupling, rapid iteration, domain context, operational integration, and continuous monitoring, conditions that cannot be centralized.
The future lies in embedding AI capability directly into existing network systems and the people who run them, not in segregated groups or expensive closed APIs. A federated community achieves this by integrating AI into current platforms, empowering domain teams with AI skills, running open models where the data resides, and enabling local autonomy with global consistency.
By treating AI as part of your cloud-native workload on hybrid infrastructure, organizations shift from abstract accuracy metrics to real business ROI, making the Community of Practice the true engine of enterprise AI.